







In late November of 2023, AWS made Knowledge Bases for Amazon Bedrock publicly available for the first time. The point was to give a secure way to connect machine learning models to a company’s data for Retrieval Augmented Generation (RAG, for short). This helps the machine learning model generate more relevant responses and answer questions about things that are not pre-trained into the model.
This blog post will walk you through a demo of RAG on Amazon Bedrock, as NordHero has envisioned it. We’ll first discuss RAG in general and then show the demo built with ReactJS and AWS.
Why use RAG?
RAG allows you to incorporate custom data into pre-trained machine learning models without exposing the data publicly. This allows the AI to improve it’s responses with the provided data, that is not available to it otherwise. For an example, you could give the model your company’s financial records and then prompt the AI to generate a report based on the records.
By using RAG, you can take advantage of large language models even when working with data you wish to keep private. You can also get a lot more personalized responses for your users by introducing custom data to the AI. Overall, RAG represents an advancement in natural language processing, offering the ability to generate noticeably more diverse and contextually relevant responses.
For more information about RAG, check out this video from AWS re:Invent 2023: Use RAG to improve responses on generative AI applications
Our RAG demo built on Amazon Web Services
As stated earlier, AWS offers RAG capabilities through their Amazon Bedrock service’s Knowledge Bases feature. Amazon Bedrock is a fully managed service that offers it’s users access to high-performing foundation models from top AI companies such as Anthropic, Cohere and Meta. Bedrock is serverless and allows the use of the foundation models through a single API, making building AI applications on AWS easy. This combined with the Knowledge Bases feature enables you to introduce your data securely and privately to the foundation models.
The security starts from the data being stored in S3, which is encrypted by default. You can also use AWS KMS to encrypt the data with keys that you manage. The data stays within your AWS environment and even when you give a public AI model access to your documents, they are not accessible by others using the same model. You can also use AWS PrivateLink to establish a private connectivity from your VPC to Amazon Bedrock, without having to expose your VPC to internet traffic. And after the data is deleted from the knowledge base, it will not be available to the AI.
We wanted to make a small RAG application, using Amazon Bedrock and other serverless services, to demonstrate how the technology can be used in the real world. The app consists of a chat interface where the user can ask questions about documents in the knowledge base. See image below.
Figure 1: Text field ready for user’s prompt
For the demo, we put some custom data into a S3 bucket that serves as the knowledge base from where Amazon Bedrock will retrieve documents that are relevant to the user’s prompt. The response will then be generated by using information found in the documents.
The knowledge base contains the Finnish 2023-2024 IT Service Industry Collective Agreement. Below you can see how the AI generates an answer to the question “Is dental care covered by the employer?”, based on the information in the knowledge base. The original document used for RAG can be found here: https://ytn.fi/sopimus/collective-agreement-of-the-it-service-sector-3-3-2023-30-11-2024/
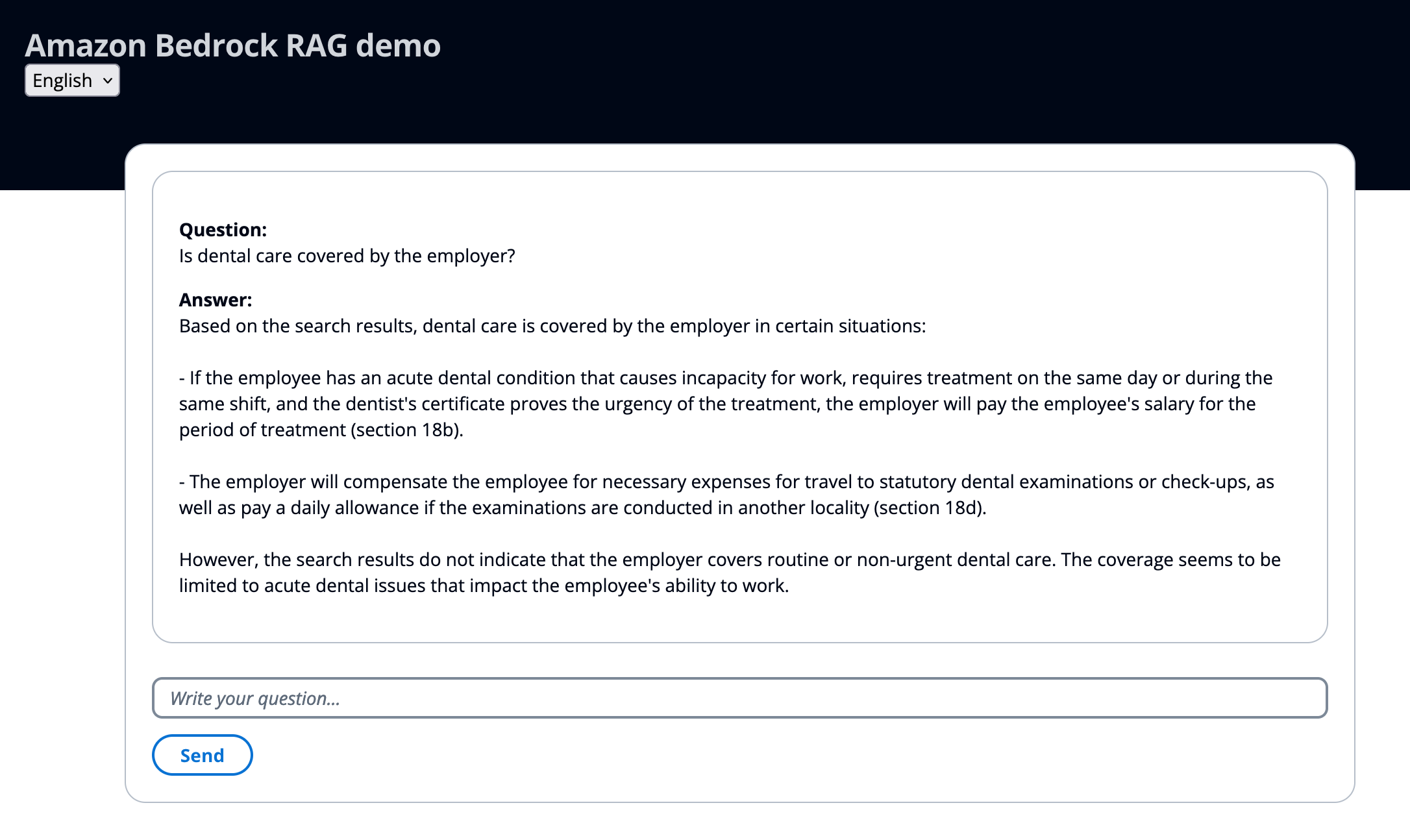
Figure 2: Response based on the retrieved documents
See this video of the demo in action:
As you can see in the video, the AI is able to generate responses in both Finnish and English, regardless of the language in which the documents are in. Even when switching languages between questions.
What’s it made out of?
The whole architecture on AWS consists of API Gateway, Lambda, Amazon Bedrock, S3 and Amazon OpenSearch Service. The knowledge base, used for RAG, is the documents stored in the S3 bucket. They can be in a wide range of formats, such as .pdf, .docx, .txt and .csv. The S3 bucket is turned into a knowledge base by using Amazon Bedrock’s knowledge base feature, which uses a text embeddings model of your choice to vectorize the documents in the bucket. We decided to use Cohere Embeddings model since it supports Finnish.
You just choose what S3 bucket to use, then you set up a vector database (you can use Amazon OpeanSearch Serverless, Pinecone or Redis, for an example) and then you’re done setting up the data source for the knowledge base. After this, you just make sure your S3 bucket has all the desired documents and then sync the data source. All of this can be with the AWS console or programmatically.
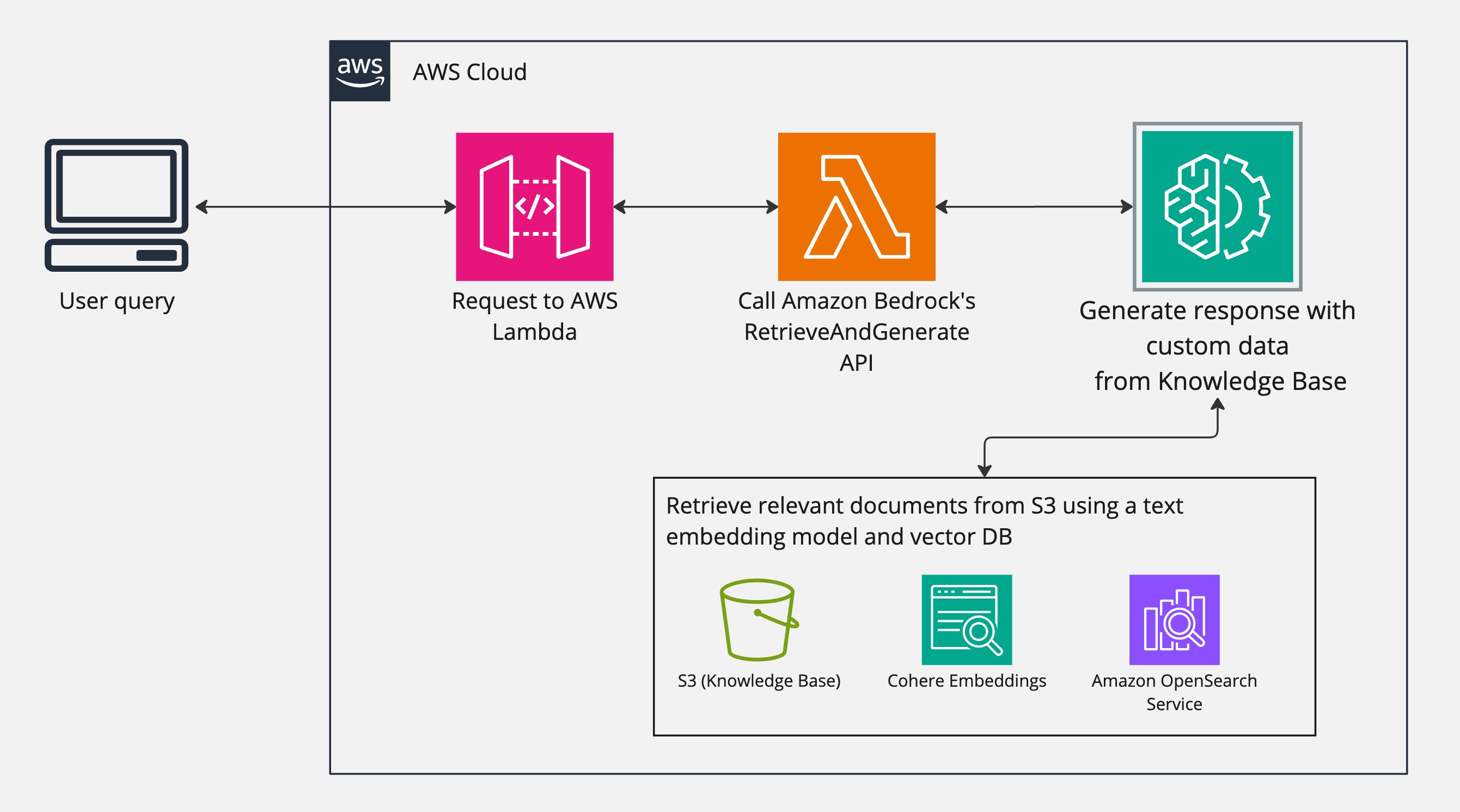
Figure 3: Architecture diagram
The frontend of the demo was build with ReactJS (styling done with Cloudscape). The user’s prompt from the frontend is sent to a Lambda function via API Gateway. The Lambda function then calls Amazon Bedrock’s RetrieveAndGenerate API that retrieves documents from the knowledge base and generates an response using a text model of your choice. We chose Anthropics Claude 3 Haiku, since we want the response fast and it doesn’t have to be that long.
Final thoughts
This demo was a really interesting project to work on and I’m very pleased with the results. The text model answers perfectly in Finnish or English and quickly retrieve data relevant to the prompt. As a small bonus, I added another Lambda function that retrieves blog posts from the AWS News Blog RSS-feed and saves them to the knowledge base S3. This goes to show how easily you could automate the ingestion of new data to the knowledge base.
A perfect use case for RAG, in my opinion, would be to use it for advanced internal document searching. Sometimes you have a suspicion that a piece of information is somewhere in your organizations documents but you aren’t sure where it can be found. In this scenario, it would be perfect to just ask a text model for the information and where it can be found. This would save a lot of time in the long run and make working with a large volume of internal documents a whole lot easier. Espcially, if you’re new to the organization.
Another sweetspot for this kind of functionality would be an automated customer service chatbot, which would have the customer service knowledge base, company’s public website, and perhaps the existing customer service transcript history as the source. Of course, any personal information would need to be first taken away from the source data.
AI tools, like ChatGPT, are being used everyday in the modern workplace, but pre-trained large language models have the limitation that they only know about data that they’ve been trained on. And you wouldn’t give your internal information sources to train a public AI service. Amazon Bedrock, Retrieval Augmented Generation and NordHero’s expertise can solve this issue by securely and privately bringing the efficiency of AI to any data you give it access to.