







Rust is a programming language that boasts a decent amount of safety features without compromising on runtime efficiency. This makes it an appealing choice for AWS Lambda, where we pay for the service by the millisecond.
In this article, we’ll take a look at cargo-lambda, an extension for cargo which makes it easy to deploy Rust programs in AWS Lambda. We will write and deploy three small Lambda functions in both Rust and Typescript:
- Hello world (to find out a baseline startup performance)
- Fibonacci (CPU-bound)
- DynamoDB reader (I/O bound)
The expectation is that Rust should give us some sort of a performance benefit in 1 and 2. It will probably not make much of a dent for 3, because most of the time spent there is waiting for the network. Another expectation is that Rust code will be slightly more cumbersome and syntax-heavy whereas Typescript will give us a slightly cleaner implementation.
Let’s see what happens!
We expect a working understanding of the technologies used, so here’s a list of primers
- Rust (https://doc.rust-lang.org/book/, https://jasonwalton.ca/rust-book-abridged/, https://google.github.io/comprehensive-rust/welcome.html)
- Typescript (https://www.typescriptlang.org/docs/)
- Cargo (https://doc.rust-lang.org/cargo/guide/)
- CDK (https://docs.aws.amazon.com/cdk/v2/guide/work-with-cdk-typescript.html)
Dependencies that need to be installed:
- Rustup
- Cargo-lambda
All the code listed on this article is available at https://github.com/NordHero/blogposts-vk/tree/main/2023-rvtoal
Laying the foundation with CDK
We’ll need a DynamoDB table, an API Gateway and references to all six Lambda functions. To start, let’s initialize the CDK project and install cargo-lambda-cdk:
mkdir 2023-rvtoal && cd 2023-rvtoal
cdk init app --language=typescript
npm install cargo-lambda-cdk @types/aws-lambda @aws-cdk/aws-apigateway2-alpha bignumber.js @aws-sdk/client-sts @aws-cdk/client-dynamodb
This creates a new CDK project and gives us a CDK entrypoint in bin/blog-article.ts, referred to in package.json. The CDK stack is defined in the BlogArticleStack class, located in lib/blog-article-stack.ts. That’s where we’ll add our resources.
Here’s the DynamoDB table:
const itemsTable = new dynamodb.Table(this, "Items", {
tableName: `${Stack.of(this).stackName}-Items`,
partitionKey: { name: "PK", type: dynamodb.AttributeType.STRING },
sortKey: { name: "SK", type: dynamodb.AttributeType.STRING },
tableClass: TableClass.STANDARD_INFREQUENT_ACCESS,
billingMode: BillingMode.PAY_PER_REQUEST,
});
Then we add references to the Typescript Lambda handlers:
const jsConfig = {
environment: {
DEBUG: "false",
},
runtime: Runtime.NODEJS_18_X,
timeout: Duration.seconds(10),
};
const tsHelloWorldFn = new NodejsFunction(this, "helloworld", {
...jsConfig,
description: "Hello World / Typescript",
});
const tsDynamodbFn = new NodejsFunction(this, "dynamodb", {
...jsConfig,
environment: {
...jsConfig.environment,
TABLE_NAME: itemsTable.tableName,
},
description: "DynamoDB / Typescript",
});
const tsFibonacciFn = new NodejsFunction(this, "fibonacci", {
...jsConfig,
description: "Fibonacci / Typescript",
});
And the Rust Lambda handlers:
const rustHelloWorldFn = new RustFunction(this, "helloworld-rs", {
manifestPath: "helloworld/Cargo.toml",
description: "Hello World / Rust",
});
const rustDynamodbFn = new RustFunction(this, "dynamodb-rs", {
manifestPath: "dynamodb/Cargo.toml",
environment: {
TABLE_NAME: itemsTable.tableName,
},
description: "DynamoDB / Rust",
});
const rustFibonacciFn = new RustFunction(this, "fibonacci-rs", {
manifestPath: "fibonacci/Cargo.toml",
description: "Fibonacci / Rust",
});
Finally, we will need to declare our API Gateway and a bit of boilerplate so we can point our Lambda handlers to it.
const rustHelloWorldIntegration = new HttpLambdaIntegration(
"Rust Hello World",
rustHelloWorldFn
);
const rustFibonacciIntegration = new HttpLambdaIntegration(
"Rust Fibonacci",
rustFibonacciFn
);
const rustDynamodbIntegration = new HttpLambdaIntegration(
"Rust DynamoDB",
rustDynamodbFn
);
const tsHelloWorldIntegration = new HttpLambdaIntegration(
"Typescript Hello World",
tsHelloWorldFn
);
const tsFibonacciIntegration = new HttpLambdaIntegration(
"Typescript Fibonacci",
tsFibonacciFn
);
const tsDynamodbIntegration = new HttpLambdaIntegration(
"Typescript DynamoDB",
tsDynamodbFn
);
const api = new HttpApi(this, "API Gateway");
api.addRoutes({
path: "/rust/hello",
methods: [HttpMethod.GET],
integration: rustHelloWorldIntegration,
});
api.addRoutes({
path: "/rust/fibonacci",
methods: [HttpMethod.GET],
integration: rustFibonacciIntegration,
});
api.addRoutes({
path: "/rust/dynamodb",
methods: [HttpMethod.GET],
integration: rustDynamodbIntegration,
});
api.addRoutes({
path: "/ts/hello",
methods: [HttpMethod.GET],
integration: tsHelloWorldIntegration,
});
api.addRoutes({
path: "/ts/fibonacci",
methods: [HttpMethod.GET],
integration: tsFibonacciIntegration,
});
api.addRoutes({
path: "/ts/dynamodb",
methods: [HttpMethod.GET],
integration: tsDynamodbIntegration,
});
The above declares the following HTTP endpoints:
GET /rust/hello
GET /rust/dynamodb
GET /rust/fibonacci
GET /ts/hello
GET /ts/dynamodb
GET /ts/fibonacci
To run this, you will need to set up your AWS credentials locally, and then just run cdk deploy. Also cdk bootstrap is needed before running any cdk commands into an environment, but I’ve omitted that here.
cdk deploy
The foundation is now built, and we can start adding the handlers.
Hello world
Our first guest doesn’t need introductions, so here is everyone’s favorite Hello World.
Typescript:
import { APIGatewayProxyHandler } from "aws-lambda";
export const handler: APIGatewayProxyHandler = async () => {
return {
statusCode: 200,
headers: {
"Content-Type": "text/html",
},
body: '<!DOCTYPE html><html lang="en"><body><p>Hello world</p></body></html>',
};
};
Rust:
use lambda_http::{run, service_fn, Body, Error, Request, Response};
async fn function_handler(_event: Request) -> Result<Response<Body>, Error> {
let message = "<!DOCTYPE html><html lang=\"en\"><body><p>Hello world</p></body></html>";
let resp = Response::builder()
.status(200)
.header("content-type", "text/html")
.body(message.into())
.map_err(Box::new)?;
Ok(resp)
}
#[tokio::main]
async fn main() -> Result<(), Error> {
tracing_subscriber::fmt()
.with_max_level(tracing::Level::INFO)
.with_target(false)
.without_time()
.init();
run(service_fn(function_handler)).await
}
The verbosity of Rust can be already seen here, but we’ll get back to that later in the larger examples.
Fibonacci
In this example, we calculate a rather big Fibonacci, n=12345. TypeScript uses the bignumber library (which is the fastest I could find that would give me correct answers), and Rust uses num_bigint.
You might say that this example is a bit skewed to make Rust look good. Then again, Rust is good – perhaps even optimal – on CPU -bound things.
Here’s Typescript:
import { APIGatewayProxyHandler } from "aws-lambda";
import { BigNumber } from "bignumber.js";
const fibonacci = (n: number): BigNumber => {
let a = new BigNumber(0);
let b = new BigNumber(1);
for (let i = 0; i < n; i++) {
[a, b] = [b, a.plus(b)];
}
return a;
};
export const handler: APIGatewayProxyHandler = async () => {
const n = 12345;
const answer = fibonacci(n);
return {
statusCode: 200,
headers: {
"Content-Type": "text/html",
},
body: `<!DOCTYPE html><html lang="en"><body><p>${n}nth Fibonacci is ${answer.toFixed()}</p></body></html>`,
};
};
And Rust:
use lambda_http::{run, service_fn, Body, Error, Request, Response};
use num_bigint::BigUint;
use std::mem;
fn fibonacci(n: u64) -> BigUint {
let mut a: BigUint = "0".parse().unwrap();
let mut b: BigUint = "1".parse().unwrap();
for _ in 0..n {
mem::swap(&mut a, &mut b);
b += &a;
}
a
}
async fn function_handler(_event: Request) -> Result<Response<Body>, Error> {
let n = 12345;
let answer = fibonacci(n);
let message = format!(
"<!DOCTYPE html><html lang=\"en\"><body><p>{}nth Fibonacci is {}</p></body></html>",
n, answer
);
let resp = Response::builder()
.status(200)
.header("content-type", "text/html")
.body(message.into())
.map_err(Box::new)?;
Ok(resp)
}
#[tokio::main]
async fn main() -> Result<(), Error> {
tracing_subscriber::fmt()
.with_max_level(tracing::Level::INFO)
.with_target(false)
.without_time()
.init();
run(service_fn(function_handler)).await
}
On the Rust side we make use of std::mem::swap to switch the integers. While extremely fast, it’s concise and idiomatic, so I figured it’s fine.
DynamoDB
For this, we’ll first want to have a bit of data in there. We did that with Rust, generating fake data with the “fake” crate. The code for this is not the main focus of the article, but you can find the generator under data-generator in git if you want to check it out. The generator gives us 1000 rows with reasonably random gibberish data.
Our actual lambda handlers will read that data and generate an HTML table. Here’s the Typescript code for that:
import { APIGatewayProxyHandler } from "aws-lambda";
import {
DynamoDBClient,
QueryCommand,
QueryCommandInput,
QueryCommandOutput,
} from "@aws-sdk/client-dynamodb";
const DYNAMODB_TABLE_NAME = process.env.TABLE_NAME!;
const DYNAMODB_CLIENT = new DynamoDBClient({});
const query_dynamodb = (): Promise<QueryCommandOutput> => {
const queryInput: QueryCommandInput = {
TableName: DYNAMODB_TABLE_NAME,
ExpressionAttributeNames: {
"#user_id": "PK",
},
ExpressionAttributeValues: {
":user": { S: "USER#rustin" },
},
KeyConditionExpression: "#user_id = :user",
};
const queryCommand: QueryCommand = new QueryCommand(queryInput);
return DYNAMODB_CLIENT.send(queryCommand);
};
type Item = {
PK: { S: string };
title: { S: string };
description: { S: string };
price: { N: string };
};
export const handler: APIGatewayProxyHandler = async () => {
const items = (await query_dynamodb()).Items! as Item[];
let results = "<table>";
for (const item of items) {
results += `<tr><td>${item.PK.S!}</td><td>${item.title.S!}</td><td>${item
.description.S!}</td><td>${item.price.N!}</td></tr>`;
}
results += "</table>";
return {
statusCode: 200,
headers: {
"Content-Type": "text/html",
},
body: `<!DOCTYPE html><html lang="en"><body>${results}</body></html>`,
};
};
The corresponding Rust code is as follows:
use lambda_http::{lambda_runtime::Error, run, service_fn, Body, Request, Response};
use lazy_static::lazy_static;
use rusoto_core::Region;
use rusoto_dynamodb::{AttributeValue, DynamoDb, DynamoDbClient, QueryInput};
use serde::Deserialize;
use std::env;
use std::fmt::Write;
lazy_static! {
static ref DYNAMO_DB_CLIENT: DynamoDbClient = DynamoDbClient::new(Region::default());
static ref TABLE_NAME: String = env::var("TABLE_NAME").expect("Cannot read TABLE_NAME");
}
#[derive(Debug, Deserialize)]
struct Item {
pk: String,
title: String,
description: String,
price: String,
}
async fn query_dynamodb(client: &DynamoDbClient) -> Result<Vec<Item>, Error> {
let query_input = QueryInput {
table_name: TABLE_NAME.to_string(),
expression_attribute_names: Some(
[("#user_id".to_string(), "PK".to_string())]
.iter()
.cloned()
.collect(),
),
expression_attribute_values: Some(
[(
":user".to_string(),
AttributeValue {
s: Some("USER#rustin".to_string()),
..Default::default()
},
)]
.iter()
.cloned()
.collect(),
),
key_condition_expression: Some("#user_id = :user".to_string()),
..Default::default()
};
let result = client.query(query_input).await?;
let items: Vec<Item> = result
.items
.unwrap_or_default()
.into_iter()
.map(|item| Item {
pk: item["PK"].s.clone().unwrap(),
title: item["title"].s.clone().unwrap(),
description: item["description"].s.clone().unwrap(),
price: item["price"].n.clone().unwrap(),
})
.collect();
Ok(items)
}
async fn function_handler(_: Request) -> Result<Response<Body>, Error> {
let items = query_dynamodb(&DYNAMO_DB_CLIENT).await?;
let mut results = String::from("<table>");
for item in items {
writeln!(
&mut results,
"<tr><td>{}</td><td>{}</td><td>{}</td><td>{}</td></tr>",
item.pk, item.title, item.description, item.price
)?;
}
results.push_str("</table>");
let html = format!(r#"<!DOCTYPE html><html lang="en"><body>{results}</body></html>"#);
Ok(Response::builder()
.status(200)
.header("Content-Type", "text/html")
.body(Body::from(html))
.unwrap())
}
#[tokio::main]
async fn main() -> Result<(), Error> {
tracing_subscriber::fmt()
.with_max_level(tracing::Level::INFO)
.with_target(false)
.without_time()
.init();
run(service_fn(function_handler)).await
}
One thing to bring home from these examples: remember to initialize your clients (in this case, the DynamoDB client) outside of the handler. Since Lambda functions persist their runtime after the cold start, the client initialization can become a significant overhead. In this case, the Rust code went down from roughly >200ms to ~40ms and there were similar improvements for TypeScript.
Code evaluation
Let’s start with the objective facts. The Hello World and Fibonacci methods are rather simple, while the DynamoDB client is approaching something you might see in the real world. So let’s focus there.
We follow The Computer Language Benchmarks Game and use two figures here: Lines of Code and gzip length.
| Implementation | Lines of Code | Gzip length |
|---|---|---|
| DynamoDB / Rust | 93 | 1081 |
| DynamoDB / TypeScript | 52 | 666 |
I’ll refrain from making any theological observations at this point.
The TypeScript code is clearly more concise, and in a way that most probably would show in larger codebases as well. Let’s check out an example. This piece of code defines the search parameters we use for the DynamoDB query:
const queryInput: QueryCommandInput = {
TableName: DYNAMODB_TABLE_NAME,
ExpressionAttributeNames: {
"#user_id": "PK",
},
ExpressionAttributeValues: {
":user": { S: "USER#rustin" },
},
KeyConditionExpression: "#user_id = :user",
};
There’s no ceremony, everything is leading towards creating the data structure. In Rust, however, there is plenty more:
let query_input = QueryInput {
table_name: TABLE_NAME.to_string(),
expression_attribute_names: Some(
[("#user_id".to_string(), "PK".to_string())]
.iter()
.cloned()
.collect(),
),
expression_attribute_values: Some(
[(
":user".to_string(),
AttributeValue {
s: Some("USER#rustin".to_string()),
..Default::default()
},
)]
.iter()
.cloned()
.collect(),
),
key_condition_expression: Some("#user_id = :user".to_string()),
..Default::default()
};
Rust likes to be explicit and the base language tries to be simple. In the Rust standard library, strings primarily come in two types: str and String. All literal strings are references to str, and therefore more efficient. However, they are not very flexible. String types work more like strings in many other languages, but as Rust likes to be explicit, conversions between these are also explicit.
Another differentiating factor is that Rust doesn’t have an object literal syntax directly equivalent to the JSON-like syntax that JavaScript/TypeScript does. In Rust, you’ll be creating and manipulating data using structs, while in TypeScript, you can create and manipulate object literals inline.
Thirdly, one of Rust’s focus areas is zero-cost abstractions, which can give us near optimal runtime performance, but may sometimes hurt the beginning developer.
Generally speaking, Rust’s typing discipline is stricter and more powerful: it allows less leeway where in TypeScript you can (depending on your project settings) leave typing information out if you so decide. In many projects, high level of type safety is not quite necessary, and getting things out the door often is. Sometimes, Rust is more flexible, for instance as can be seen in the Fibonacci code:
mem::swap(&mut a, &mut b); // Rust
b += &a;
[a, b] = [b, a.plus(b)]; // Typescript
Here, Rust allows overloading the standard + operator even though we are manipulating values defined with a 3rd party library.
Rust derives a lot of its performance from the fact that it gets compiled down to a binary. But since AWS Lambda does not have any special support for Rust, this compilation needs to be done at deployment. This means that there’s no access to the code in Lambda’s console.
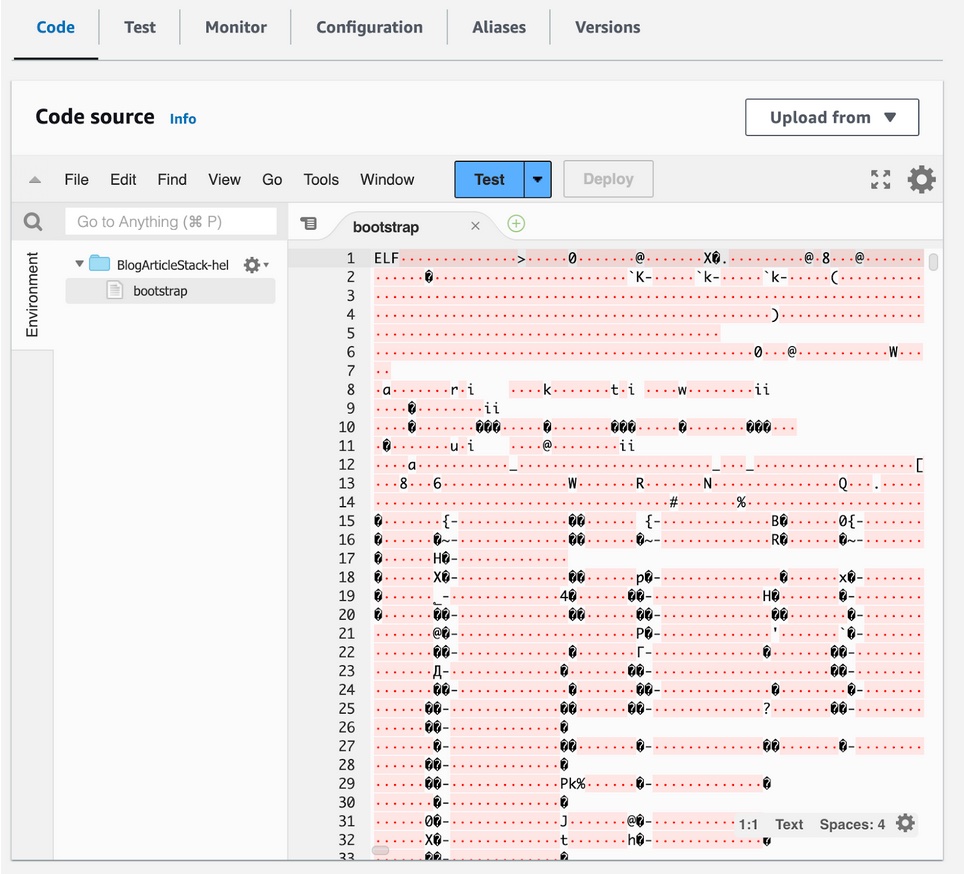
Typescript is also not directly supported by AWS Lambda, but it transpiles to Javascript, which is. Therefore you can make at least some adjustments to the code via the console, which may be very useful in debugging situations.
Performance evaluation
Evaluation strategy was as follows:
- Deploy
- Generate data for the DynamoDB benchmark
- Call the API gateway once, record cold start time in Lambda / Cloudwatch
- Call the API gateway 10 times, ignore those (TypeScript seemed to have some trouble getting up to speed, so I gave it a little slack)
- Call the API gateway 10 times, record those in Lambda / Cloudwatch
- Enter the runtime average to https://calculator.aws with 10^9 monthly requests to get a cost estimate
The results:
| Implementation | Cold start (ms) | Runtime average (ms) | Runtime standard deviation (ms) | Memory average (MB) | Monthly cost (10^9 requests) | Runtime cost (base cost removed) |
|---|---|---|---|---|---|---|
| Hello World / TypeScript | 20 | 2 | 0 | 68 | $200 | $0 |
| Hello World / Rust | 71 | 1.1 | 0.32 | 18 | $200 | $0 |
| Fibonacci / Typescript | 824 | 295.4 | 24.95 | 76.4 | $807 | $607 |
| Fibonacci / Rust | 103 | 2.6 | 1.90 | 19 | $200 | $0 |
| DynamoDB / Typescript | 759 | 150 | 61.49 | 101.1 | $506 | $306 |
| DynamoDB / Rust | 831 | 36.1 | 6.74 | 29.9 | $268 | $68 |
For Hello World, we’re looking at rather similar values, and somehow cold results are much faster for Typescript. For warm results, Rust results were 82 faster for Fibonacci, and 4 times faster for the solution DynamoDB. Rust solutions also used several times less memory than Typescript, although 128MB is the minimum amount that Lambda executions can use. Also, Rust implementations showed much lower deviation in runtime, i.e. more stable performance.
The much faster CPU bound solution for Rust was not surprising, especially given the large input value of 12345, which forced the use of arbitrary-precision integers. The several times faster DynamoDB results were somewhat a surprise – we expected that part to be about as efficient in both implementations due to the I/O. It might be that most of the time was spent in building the response string after all.
As for the costs, the differences are smaller than the runtime averages would suggest. This is because $200 is the base cost for 10^9 requests, and the CPU cost of both Hello Worlds and Fibonacci / Rust falls under the free tier.
Summary
Rust code is somewhat more complex, but also much more efficient than Typescript. On the positive side, Rust functions are directly cheaper, faster and safer than Typescript. Typescript functions on the other hand are shorter and simpler.
Here is a simplified decision chart on the pros and cons of these languages for AWS Lambda.
| Rust | Typescript | |
|---|---|---|
| Runtime performance | + | - |
| Clarity of code | - | + |
| Debuggability (in AWS Lambda) | - | + |
| Safety | ++ | + |
| Operative cost for most cases | + | + |
| Operative cost for CPU heavy functions | + | - |
We started with the expectation that an implementation written on Rust would have higher performance, but how much it mattered for the DynamoDB test that seemed IO-bound was surprising. There was a difference in operative cost especially for the most CPU heavy operation, but it was less significant than expected.
It remains to be seen if Rust will become more popular as a language for AWS Lambda functions, and whether AWS will have more direct support for it. There are certainly some performance promises here.