







In this five-part blog series, I’ll explore how much speed improvement can be achieved when a simple sequential logic is converted to a concurrent implementation. I’ll evaluate the performance differences across different programming languages in an AWS Lambda function with different resource configurations. The 6 different programming languages are: Python, Node.js, Go, Rust, Java and C++.
You can jump directly to the different articles in this series, published on Medium platform:
- How do you like your AWS Lambda Concurrency: Part 1 - Introduction
- How do you like your AWS Lambda Concurrency: Part 2 - Python and Node.js
- How do you like your AWS Lambda Concurrency: Part 3 - Go and Rust
- How do you like your AWS Lambda Concurrency: Part 4 - Java and C++
- How do you like your AWS Lambda Concurrency: Part 5 - Summary (this article)
This is the summary of our blog series. Here we wrap up the findings and results from the other four articles.
Introduction
Concurrency refers to an approach where a workload is split into smaller tasks and their execution overlaps, allowing them to progress simultaneously. Concurrent execution can also be parallel in an execution environment where multiple processing units or cores or higher architectural constructs can be utilized. Concurrency is especially useful approach when the workload is IO-bound, which is the case e.g. when making network requests. In such case converting a sequential (i.e. one after another type) implementation to concurrent one will lead to great performance improvements.
With each of the chosen languages we implement a simple logic, which lists the objects from a specified AWS S3 bucket and then reads each objects’ content and calculates the execution time. We use the most typical approach to implement concurrent logic in each language. Python and Node.js will be restricted to a single thread whereas other languages can use multiple threads and processing units when there are such available. The following list describes the concurrency approach with each language:
| Language | Concurrency approach | Threads |
|---|---|---|
| Python | Built-in asyncio with async/await using aioboto as an asynchronous wrapper around AWS SDK for Python’s synchronous API | Single |
| Node.js | Built-in async/await using AWS SDK asynchronous API | Single |
| Go | Built-in goroutines and channels using AWS SDK synchronous API | Multiple |
| Rust | Separate Tokio asynchronous runtime with async/await using AWS SDK asynchronous API | Multiple |
| Java | Built-in Concurrency Framework and CompletableFuture-class with AWS SDK asynchronous API | Multiple |
| C++ | Built-in Async and Futures using AWS SDK synchronous API | Multiple |
AWS Lambda was used as an execution environment because it supports up to 6 virtual CPUs and it’s easy to configure execution environment’s resources easily. Approach used here for benchmarking purposes is no by means a recommended way to design and implement typical workload processing. Generally it’s much better to implement processing so that you utilize cloud services’ in a way that you achieve true parallelism and can easily recover from error situations where processing of some tasks fails.
Benchmark Setup
AWS S3 gradually increases API responses’ throughput up to 5500 read requests per second. API throughput is per S3 prefix and therefore we have a separate prefix and copy of test objects for each of the languages (e.g. S3://<bucket_name>/python/1000). We’ll invoke different languages with specific memory configuration one after another assuming this ensures that S3 “warms-up” the API throughput resources equally.
AWS Lambda scales vCPU resources proportionally to memory size starting from a fraction of vCPU with 128MB (out of 2 CPUs reported by the runtime) and up to 6 vCPUs with 10240 MB. I chose the 10 memory configurations so that first I had two “typical” low-end configurations, then 4 configurations just below the next pricing point and finally 4 configurations where runtime reports additional vCPU at an optimal pricing point edge. The following table lists the used memory configurations and number of vCPUs reported by the runtime are the following:
| Memory (MB) | Number of vCPUs (reported by runtime) |
|---|---|
| 128 | 2 |
| 256 | 2 |
| 511 | 2 |
| 1023 | 2 |
| 3008 | 2 |
| 3071 | 2 |
| 6143 | 3 |
| 7167 | 4 |
| 9215 | 5 |
| 10240 | 6 |
There are 6 languages and 10 different memory configurations to test with. We’ll run this test cycle 3 times and then calculate an average result out of each configuration execution time in order to eliminate any exceptional delays. This means we’ll end up having 180 Lambda-function invocations, which would be too much to do manually. To automate this, we’ll use AWS Step Function to control Lambda-invocations as well as updating Lambdas’ memory configuration according to our needs using UpdateFunctionConfiguration-Action.
Each implementation reports the results in JSON format so we’ll collect the responses from Lambda invocations in Step Function. The Final step is just to perform some analysis and visualization in the Jupyter Notebook.
This benchmark deliberately eliminates all the delays from the Lambda runtime initialization as well as any language specific initialization that might be happening.
Benchmark Results
Before jumping to actual results let’s summarize each language version and processor architecture used in AWS Lambda. For the languages, which have an existing language specific runtime in AWS Lambda the most recent version at the time of writing was used.
| Language | Version information | CPU Architecture |
|---|---|---|
| Python | 3.11 | ARM |
| Node.js | 18.x | ARM |
| Go | 1.x, go1.20.5 | Intel |
| Rust | provided.al2, rustc 1.70 | ARM |
| Java | 17, Amazon Corretto 17 | ARM |
| C++ | provided.al2, g++ Ubuntu 11.3.0 | ARM |
Let’s start with the overall trend of execution time shown in the following figure:
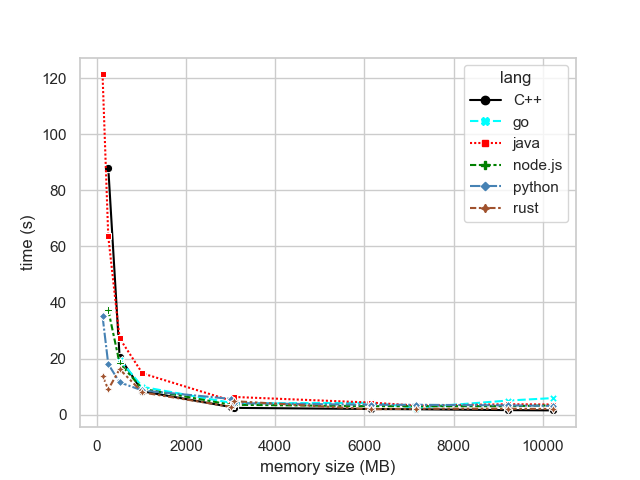
Figure 1: Overall trend of execution time
As we’d expect there’s steep improvement first while we add a bit more Lambda compute resources but then execution time settles. S3 API resources’ warm-up explain some part of steep improvement in the lower-end of memory size configurations. On the other end of spectrum we’ll be limited then by the languages’ concurrency capabilities, network delays and maybe also S3 API throttling.
Let’s then look more closely at the lower end of memory configurations starting from 128 MB until 1023 MB.
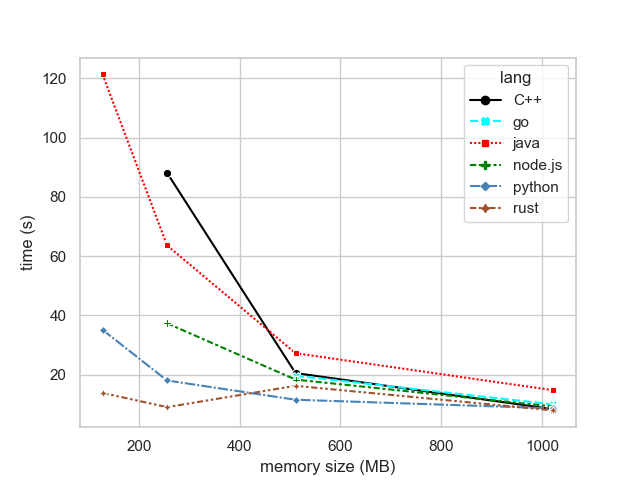
Figure 2: Overall trend, lower end of memory configurations
| memory size (MB) | python | node.js | go | rust | java | C++ |
|---|---|---|---|---|---|---|
| 128 | 35.1 | NaN | NaN | 13.8 | 121.3 | NaN |
| 256 | 18.0 | 37.3 | NaN | 9.0 | 63.6 | 88.1 |
| 511 | 11.5 | 18.3 | 19.6 | 16.2 | 27.2 | 20.5 |
| 1023 | 8.6 | 9.2 | 9.9 | 7.9 | 14.7 | 8.3 |
With the Lambda minimum memory configuration at 128 MB only Python, Rust and Java we’re able to finish within timeout. Node.js and Go timeouted and C++ errored out. In the first part of this blog series we saw Python’s sequential implementation where the first run took 80 seconds and then gradually dropped down to 22.3 seconds. Here the initial execution with concurrent Python takes around 35 seconds so it’s already a good improvement. Rust starts from the impressive 13.8 seconds with the initial run with minimal Lambda resources.
On 256 MB Go errored out in all execution rounds but other languages were able to finish within the timeout limit. There’s still quite a bit of a spectrum in execution times. Python gets a steep improvement and beats Node.js with a good margin.
Things start to even out at 511 MB configuration. Now all languages were able to complete, although Go still had a hard time and only finished on one round and errored out on other two executions. For some reason here Rust takes a bump but Python continues to steadily improve.
At 1023 MB Go finally runs without errors and all languages except Java end up to an average of 8-9 seconds. Rust takes the lead back and C++ takes the second place.
In typical use cases, further gains are generally minimal when moving from this range to higher-end memory configurations. With AWS Lambda Power Tuning, you can discover the optimal Lambda configuration that strikes the right balance between cost and performance.
The following figure shows the results at the higher-end of memory configuration spectrum starting from 3008 MB up to 10240 MB.
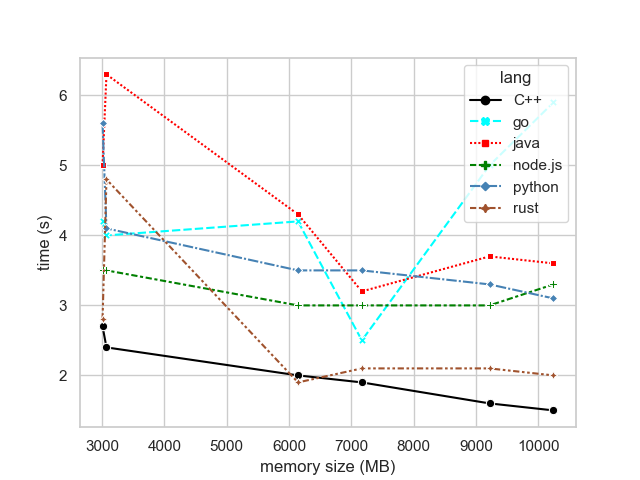
Figure 3: Overall trend, high end of memory configurations
| memory size (MB) | python | node.js | go | rust | java | C++ |
|---|---|---|---|---|---|---|
| 3008 | 5.6 | 3.5 | 4.2 | 2.8 | 5.0 | 2.7 |
| 3071 | 4.1 | 3.5 | 4.0 | 4.8 | 6.3 | 2.4 |
| 6143 | 3.5 | 3.0 | 4.2 | 1.9 | 4.3 | 2.0 |
| 7167 | 3.5 | 3.0 | 2.5 | 2.1 | 3.2 | 1.9 |
| 9215 | 3.3 | 3.0 | 5.0 | 2.1 | 3.7 | 1.6 |
| 10240 | 3.1 | 3.3 | 5.9 | 2.0 | 3.6 | 1.5 |
At first sight the results seem to be all over the place. But let’s keep in mind that we’re now scrutinizing the results almost at a microscopic level. Furthermore as we’re reading 1000 files over the Internet the network IO can have unexpected effects on the results. We can see a slight trend of improving execution time and C++ is the fastest with the high-end memory configuration. Go has its moment on 7167 MB but then drops down at the end of the pack being the slowest at 10240 MB.
The next graph shows the standard deviation among three different executions on each memory configuration.
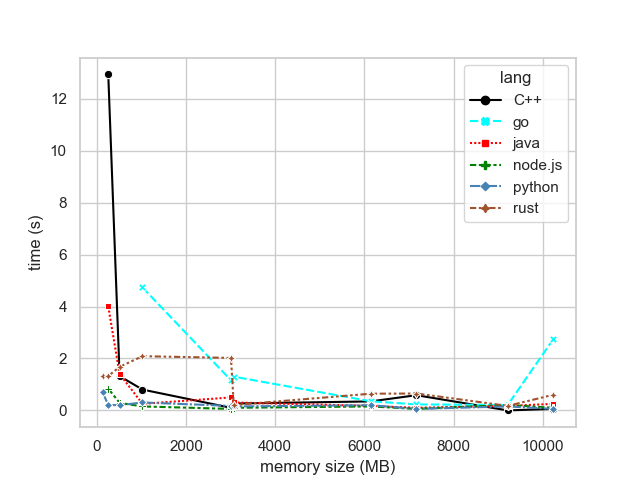
Figure 4: Standard deviation on each memory configuration
Python and Node.js have small deviations across all the memory configurations. Go has its difficulties on the lower end of the spectrum and doesn’t shine against the other languages.
Subjective Review Results
Subjective review of the languages consists of 7 categories, which cover various developer experience aspects. Here we use grades from 1 to 6 where higher is better from the developer experience aspect. For example in ‘code complexity’-category the higher grade means that code is less complex, which is better. Grade 6 doesn’t mean that the language is perfect and grade 1 doesn’t mean that it’s absolutely horrible. Grading is just a tool to compare these selected languages against each other.
The following graph show the summary results:
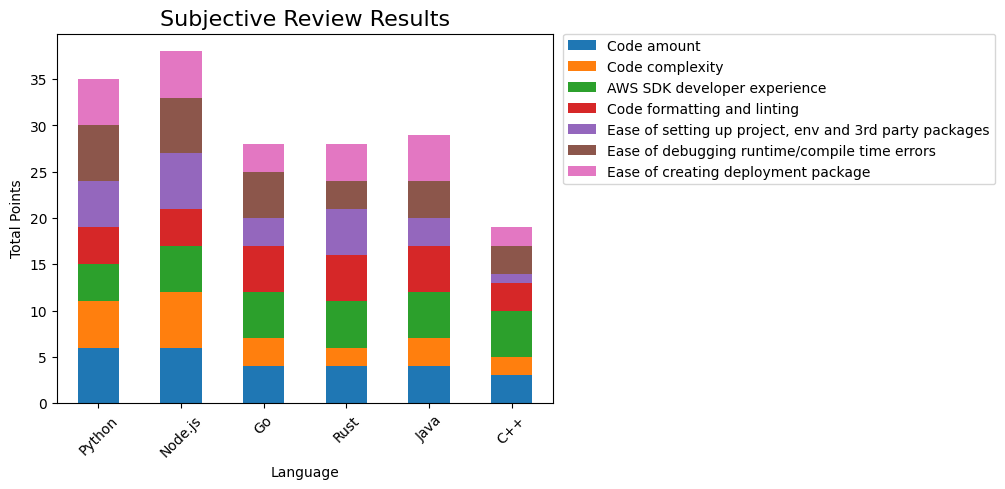
Figure 5: Subjective Review Results
Node.js hits the high score for this simple project where only dependency is AWS SDK. Python takes the second podium in this experiment for subjective review. AWS SDK for Python (boto3) doesn’t support the async programming model and we had to use a 3rd party library in our implementation. AWS must fix this deficiency quickly.
Java is surprisingly elegant and pleasant to work with. Constructs are clear and making a deployment package was hassle-free. I had thought that Java belonged to the past, but strangely, I rediscovered some old and forgotten affinity for it during this experiment.
Go has its own special approach for achieving concurrency and it kind of makes that part of the implementation straightforward. Rust syntax and constructs take time to master but concurrency constructs are similar to Python and Node.js. Rust has a very good toolchain also for developing Lambda-functions.
For such a simple project, C++ is initially quite overwhelming. However, once the setup is complete, reproducing and continuing from there becomes straightforward.
Combining Subjective and Objective Results
In order to combine subjective and objective results we need to convert objective results to some numeric grades. We use the following grading system:
- Languages are rated based on how fast they run at different AWS Lambda memory configurations. The fastest language gets the most points, and the slowest one gets the fewest. If a language fails to execute successfully, it gets zero points.
- For memory configurations between 128 MB and 1023 MB, we use a rating scale from 1 to 6 with 1-point differences. For memory settings from 3008 MB up to 10240 MB, we use a scale from 1 to 3 with 0.5-point differences. In other words we give more weight for performance on the lower end of memory configurations.
Using the above grading system we get an objective score, which we sum up with a subjective score to get a final combined score.
| Language | Subjective Score | Objective Score | Combined Score |
|---|---|---|---|
| Rust | 28 | 37.0 | 65.0 |
| Python | 35 | 27.5 | 62.5 |
| Node.js | 38 | 22.5 | 60.5 |
| C++ | 19 | 26.5 | 45.5 |
| Java | 29 | 14.0 | 43.0 |
| Go | 28 | 12.5 | 40.5 |
Rust may not be the first choice for implementing Lambda functions. It will take significantly more effort to implement your business logic compared to e.g. Python. But Rust has excellent performance starting from the lowest memory configurations and has a good toolchain that supports Lambda function development and deployments.
Python also performs well. It’s lightweight and lets you focus on business logic. Unfortunately for async code you need to use 3rd party libraries that wrap AWS SDK for Python’s synchronous only API. Python’s roadmap including development towards faster CPython gives promises for significant improvements in the near future.
Node.js is a slick language to work with simple Lambda functions if only AWS SDK is what you need. If you’re already familiar with the JavaScript ecosystem then it’s your goto solution.
Go and Java are both their own islands, where you can happily stay and build your applications. These days, choosing Java for a new project might raise some eyebrows but both languages are nice ones to work with and have good performance. Go’s performance in the benchmark was a disappointment.
C++ dominated the high-end memory configuration benchmark but it’s certainly the most complex language out of these to work with. Currently I don’t see any immediate reasons to refresh my C++ skills beyond this experiment.
Improvement from Sequential to Concurrent
Now let’s get back to where we started with the sequential Python implementation. The following diagram shows the performance gains we have achieved along the way:
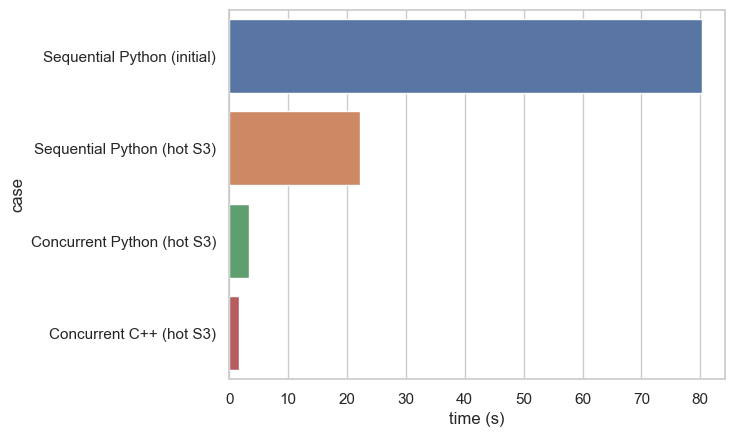
Figure 6: Improvement from Sequential to Concurrent
We started with the AWS Lambda function with Python sequentially fetching the objects from S3. While the first run took 80 seconds, after a few repetitions execution time settled to 22.3 seconds due S3 was gradually scaling up its throughput. Concurrent Python improves its performance consistently all the way up to ridiculously oversized 10240 MB AWS Lambda where the execution time was 3.1 seconds. The C++ implementation, being fastest of them all, was down at 1.5 seconds.
Final Words
I chose these 6 languages in this experiment because I have some degree of interest towards all of them. To excel as a professional developer, your ability to work confidently with a wide range of programming languages becomes increasingly valuable.
This has been a fun, laborious but educating experiment and I hope you have enjoyed reading these blog posts. Clap, comment and share these blog posts and follow me for more upcoming interesting writes. Also, experiment by yourself with the provided code!
Here are a few final notes:
- If you spot a mistake or have ideas for improving the code, please go ahead and let me know by opening an issue on the relevant GitHub repository.
- If you’re curious about how some other programming language would perform in this benchmark, I suggest giving it a try and putting the implementation together. Link me with a repository and I could put together a follow-up post with additional languages.
Links to GitHub repositories: